 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
对线性回归模型作一些基本假定的最重要原因是()
A.为了便于确定模型的解释变量
B.为了使估计的参数具有良好的统计性质
C.为了便于确定所估计参数的均值
D.为了便于得出模型参数的估计值
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.为了便于确定模型的解释变量
B.为了使估计的参数具有良好的统计性质
C.为了便于确定所估计参数的均值
D.为了便于得出模型参数的估计值
如果结果不匹配,请 联系老师 获取答案
 更多“对线性回归模型作一些基本假定的最重要原因是()”相关的问题
更多“对线性回归模型作一些基本假定的最重要原因是()”相关的问题
A.⑤
B.①③④⑤
C.①②③④
D.①②④⑤
为另一种形式:斜率与原来相同,但截距和误差有所不同,并且新的误差期望值为零。
使用TRAFFIC2.RAW中的数据。
(i)做prcfat对一个线性时间趋势、月份虚拟变量及变量wkends,unem,spdlaw和beltlw的OLS回归。利用教材方程(12.14)中的回归检验误差中的AR(1)序列相关。使用假定了严格外生回归元的检验说得过去吗?
(ii)利用尼威-韦斯特估计量中的4阶滞后,求spdlaw和beltlaw系数的序列相关和异方差-稳健标准误。这将如何影响这两个政策变量的统计显著性?
(iii)现在,利用迭代普莱斯-温斯顿程序估计模型,并将估计值与OLS估计值进行比较。政策变量的系数或统计显著性有重大变化吗?
A.二元线性回归
B.二元二次线性回归
C.多元线性回归
D.一元线性回归
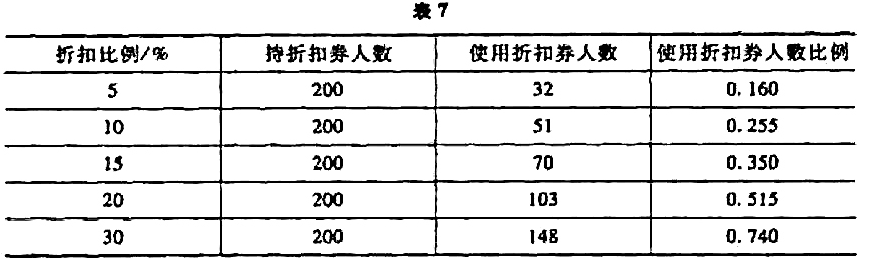
(1)对使用折扣券人数比例先作logit变换,再对使用折扣券人数比例与折扣比例,建立普通的一元线性回归模型。
(2)直接利用MATLAB统计工具箱中的glmfit命令,建立使用折扣券人数比例与折扣比例的logit模型.与(1)作比较.并估计着想要使用折扣券人数比例为25%,则折扣券的折扣比例应该为多大?
A.异方差
B.完全多重共线
C.遗漏变量偏差
D.虚拟变量陷阱
(x)=x2或g(x)=log(1+x2) 。定义zi=g(xi)定义一个斜率估计量为
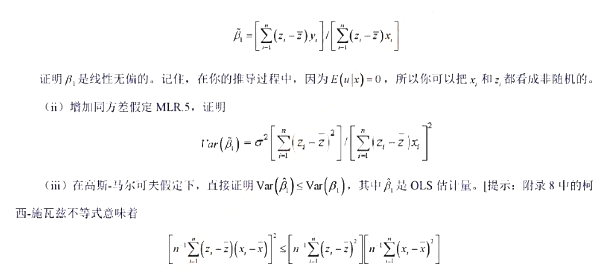
A.向前选择法是从模型中没有自变量开始,然后将所有自变量依次增加到模型中
B.向后剔除法是先对所有自变量拟合线性回归模型,然后依次将所有自变量剔除模型
C.逐步回归法是将向前选择法和向后剔除法结合起来,但不能保证得到的回归模型一定就显著
D.逐步回归法选择变量时,在前面步骤中增加的自变量在后面的步骤中有可能被剔除,而在前面步骤中剔除的自变量在后面的步骤中也可能重新进入到模型中
A.星点设计由二水平析因设计加轴点及中心点组成
B.是不用模拟模型的实验设计
C.是多因素五水平的试验设计
D.借助多元线性回归分析的方法来分析数据

















