 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
数据分析报告的前言部分可以从分析背景、分析目的、分析思路三个方面来撰写,其中分析思路可以从几个方面去写,以下哪个不是分析思路的撰写内容?()
A.通过哪几方面开展分析
B.如何选取分析对象
C.采集数据的方式
D.如何开展分析
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.通过哪几方面开展分析
B.如何选取分析对象
C.采集数据的方式
D.如何开展分析
如果结果不匹配,请 联系老师 获取答案
 更多“数据分析报告的前言部分可以从分析背景、分析目的、分析思路三个…”相关的问题
更多“数据分析报告的前言部分可以从分析背景、分析目的、分析思路三个…”相关的问题
利用PHILLIPS.RAW中的数据。
(i)估计失业率的AR(1)模型。用这个方程预测2004年的失业率。将它与2004年的实际失业率进行比较。(你可以从近年的《总统经济报告》中找到这个数据。)
(ii)在第(i)部分的方程中增加通货膨胀的一期滞后。inft-1统计上显著吗?
(iii)利用第(ii)部分中的方程预测2004年的失业率。这个结果比第(i)部分的结果更好还是更糟?
(iv)利用教材6.4节中的方法构造2004年失业率的一个95%的置信区间。2004年的实际失业率位于这个区间内吗?
(i)令yt代表真实个人可支配收入。用直至1989年的数据估计如下模型:
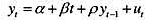
并用通常的格式报告结果。
(ii)用第(i)部分估计的方程预测1990年的y。预测误差是多少?
(iii)用第(i)部分估计的参数,计算20世纪90年代提前一期预测值的MAE。
(iv)把yt-1从方程中去掉后,计算相同时期内的MAE。在模型中包含yt-1更好些吗?
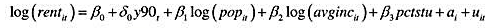
其中pop是城市人口,avginc是平均收入,而petstu是学生人口占城市人口的百分数(按学年计算)。
(i)用混合OLS估计方程并按标准方式报告结果。你如何理解1990年虚拟变量的估计值?你得到βpctstu是多少?
(ii)你在第(i)部分中报告的标准误是否真实?请解释。
(iii)现在,将方程差分并用OLS估计。把你对βpctstu的估计值和第(ii)部分进行比较。学生人口的相对规模对房租有影响吗?
(iv)对第(ii)部分中的一阶差分方程求异方差-稳健的标准误。这是否改变了你的结论?
A.数据库的集中
B.数据的水平分布
C.数据的垂直分布
D.数据的复制
客户义务与公司义务一般体现在理财规划方案书中的()部分。
A.前言
B.摘要
C.正文
D.结尾
利用JTRAIN3.RAW中的数据。
(i)估计简单回归模型re78=β0+β1train+u,并用常用格式报告结论。基于这个回归,1976年和1977年的工作培训看上去对1978年的真实劳动工资有正的影响吗?
(ii)现在使用真实劳动工资的变化cre=re78-re75作为因变量。(由于我们假定1975年之前没有工作培训,所以我们没有必要对train进行差分。也就是说,如果我们定义ctrain=train78-train75,那么,由于train75=0,所以ctrain=train78.)现在,培训的估计影响有多大?讨论它与第(i)部分估计值的比较。
(iii)利用通常的OLS标准误和异方差-稳健标准误求培训效应的95%置信区间,并描述你的结论。
在理财规划方案建议书中需要约定客户义务,这部分主要包含在()部分中。
A.前言
B.摘要
C.假设前提
D.正文
使用PNTSPRD.RAW中的数据。
(i)变量sprdcvr是一个二值变量,若在大学篮球比赛中实际分数差距超过拉斯维加斯让分,则此变量取值1。sprdcvr的期望值(比方说u)表示在一场随机抽取的比赛中分差超过让分的概率。在10%的显著性水平上相对于H1:μ≠0.5检验H0:μ=0.5,并讨论你的结果。(提示:将sprdcvr只对一个截距项进行回归便得到一个r统计量,利用这个统计量很容易完成。)
(ii)553个样本中有多少场比赛是在中立场地进行的?
(iii)估计线性概率模型
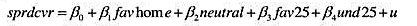
并以通常的形式报告结论。(报告通常的标准误和异方差-稳健的标准误。)哪个变量在实际上和统计上都是最显著的?
(iv)解释为什么在原假设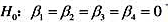 下,模型中不存在异方差性。
下,模型中不存在异方差性。
(v)利用通常的F统计量检验第(iv)部分的原假设,你得到了什么结论?
(vi)给定上述分析,你会不会认为,利用赛前可利用的信息,有可能系统地预测拉斯维加斯让分能否实现?

















