 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
为在查询结果中去掉重复记录,要使用保留字()
A.UNIQUE
B.COUNT
C.DISTINCT
D.UNION
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.UNIQUE
B.COUNT
C.DISTINCT
D.UNION
如果结果不匹配,请 联系老师 获取答案
 更多“为在查询结果中去掉重复记录,要使用保留字()”相关的问题
更多“为在查询结果中去掉重复记录,要使用保留字()”相关的问题
A.lambda函数也称为匿名函数
B.lambda函数将函数名作为函数结果返回
C.定义了一种特殊的函数
D.lambda不是Python的保留字
A.=COUNT(B1:C5)
B.=AVERAGE(B1:C5)
C.=MAX(B1:C5)
D.=Sum(B1:C5)
本题需要使用ELEM 94-95中的数据, 也可参见计算机习题C 4.10。
(i) 利用所有数据, 将lavg sal对bs, lenrol, Istaff和lunch进行回归。报告bs的系数及其常用标准误和异方差-稳健标准误。你对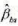 的经济显著性和统计显著性得到什么结论?
的经济显著性和统计显著性得到什么结论?
(ii)现在去掉四个bs>0.5的观测,即平均福利(假设)占平均薪水50%以上的观测。bs的系数又是多少?利用异方差-稳健标准误来判断,它在统计上显著吗?
(iii)验证bs>0.5的四个观测分别为68、1127、1508和1670。为它们各定义一个虚拟变量。(你可以称它们为d68、d1127、d 1508和d 1670.) 把它们添加到第(i) 部分的回归中, 验证其他变量的OLS系数及其标准
误与第(ii)部分中的结果相同。在5%的显著性水平上,这四个虚拟变量中哪个变量的t统计量在统计上显著不等于0?
(iv)在这个数据集中,验证第(iii)部分回归中具有最大学生化残差(该虚拟变量的t统计量最大)的数据点对OLS估计值具有很大的影响。(即利用除去具有最大学生化残差的数据点之外的所有观测进行OLS回归。)依次去掉bs>0.5的每个观测都具有重要影响吗?
(v) 即便在大样本中, 就OLS对单个观测的敏感性而言, 你有何结论?
(vi) 在第(iji) 部分, 验证LAD估计量对包含这些观测不是很敏感。
本题使用HTV.RAW中的数据。
(i)基于整个样木, 利用解释变量educ、abil、exper、nc、west、south和urban, 利用OLS估计log(wage)的一个模型。报告教育的估计回报及其标准误。
(ii)现在, 仅利用educ<16的人群来估计第(i) 部分中的方程。样本损失了多大的比例?现在, 多读一年书的估计回报是多少?它与第(i)部分中的结果相比如何?
(iii)现在, 去掉所有wage≥20的观测, 于是, 样本中剩下每个人每小时工资都不足20美元。做第(i) 部分中的回归, 并评论educ的系数。(由于正常的断尾回归模型都假定y是连续的, 所以理论上我们去掉wage≥20还是去掉wage>20都无所谓。但在这个应用研究中, 由于有些人正好每个小时挣20美元, 所以二者略有差异。)
(iv)利用第(ii) 部分中的样本, 应用断尾回归[上断点为log(20) ] .假定第(i) 部分中得到的估计值是一致的,这个断尾回归能够重新得到整个总体中的教育回报估计值吗?

















