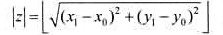题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
使用数据集TWOYEAR.RAW. (i)变量phsrank表示一个人的高中百分位等级。(数字越大越好。比如90意
使用数据集TWOYEAR.RAW. (i)变量phsrank表示一个人的高中百分位等级。(数字越大越好。比如90意
使用数据集TWOYEAR.RAW.
(i)变量phsrank表示一个人的高中百分位等级。(数字越大越好。比如90意味着,你的排名比所在班级中90%的同学更高。)求出样本中phsrank的最小、最大和平均值。
(ii)在方程(4.26)中增加变量phsrank,并照常报告OLS估计值。phsrank在统计上显著吗?高中排名提高10个百分位点,能导致工资增加多少?
(iii)在方程(4.26)中增加变量phsrank显著改变了2年制和4年制大学教育回报的结论了吗?请解释。
(iv)数据集包含了一个被称为id的变量。你若在方程(4.17)或(4.26)中增加id,预计它在统计上不会显著,解释为什么?双侧检验的p值是多少?
查看答案

 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案

 更多“使用数据集TWOYEAR.RAW. (i)变量phsrank…”相关的问题
更多“使用数据集TWOYEAR.RAW. (i)变量phsrank…”相关的问题

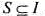 ,使得在X轴上的任何一点p,S中与直线x=p相交的开线段个数不超过k,且
,使得在X轴上的任何一点p,S中与直线x=p相交的开线段个数不超过k,且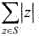 达到最大.这样的集合S称为开线段集合的最长k可重线段集,
达到最大.这样的集合S称为开线段集合的最长k可重线段集,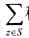 称为最长k可重线段集的长度.
称为最长k可重线段集的长度.