 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
分布滞后模型中个别滞后系数的估计值很不准确。减轻多重共线性问题的一种办法,就是假定δj具
有相对简单的形式。具体而言,考虑一个包含四期滞后的模型:
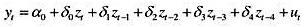
现在假定δj是j的二次函数: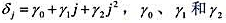 为参数。这是多项式分布滞后(polynomialdistributedlag,PDL)模型的一个例子。
为参数。这是多项式分布滞后(polynomialdistributedlag,PDL)模型的一个例子。
(i)将每个δj的公式代入分布滞后模型,并把它写成用γh表示的模型h=0,1,2。
(ii)解释你用来估计γh的回归方程。
(iii)上面的多项式分布滞后模型是一般模型的一个约束形式。它受到了多少个约束?你如何来检验它们?(提示:用F检验。)
查看答案

 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案

 更多“分布滞后模型中个别滞后系数的估计值很不准确。减轻多重共线性问…”相关的问题
更多“分布滞后模型中个别滞后系数的估计值很不准确。减轻多重共线性问…”相关的问题
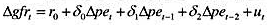
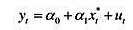
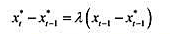
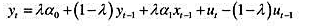
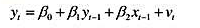
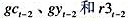 ,作为工具变量重新估计教材(16.35)。这些估计值与教材(16.36)中的那些估计值相比如何?
,作为工具变量重新估计教材(16.35)。这些估计值与教材(16.36)中的那些估计值相比如何?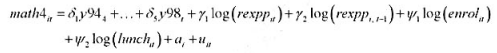
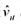 。
。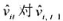 的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994~1998年的数据。验证存在很强的正序列相关,并讨论为什么。
的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994~1998年的数据。验证存在很强的正序列相关,并讨论为什么。

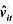 。
。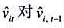 的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994-1998年的数据。验证存在很强的正序列相关,并讨论为什么。
的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994-1998年的数据。验证存在很强的正序列相关,并讨论为什么。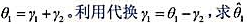 的标准误。
的标准误。
















