 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
利用CONSUMP.RAW中的数据。 (i)令yt代表真实个人可支配收入。用直至1989年的数据估计如下模
利用CONSUMP.RAW中的数据。
(i)令yt代表真实个人可支配收入。用直至1989年的数据估计如下模型:
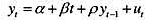
并用通常的格式报告结果。
(ii)用第(i)部分估计的方程预测1990年的y。预测误差是多少?
(iii)用第(i)部分估计的参数,计算20世纪90年代提前一期预测值的MAE。
(iv)把yt-1从方程中去掉后,计算相同时期内的MAE。在模型中包含yt-1更好些吗?
暂无答案
 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案

 更多“利用CONSUMP.RAW中的数据。 (i)令yt代表真实个…”相关的问题
更多“利用CONSUMP.RAW中的数据。 (i)令yt代表真实个…”相关的问题
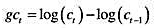 表示人均真实(非耐用消费品和服务)消费的增长。那么PIH意味着
表示人均真实(非耐用消费品和服务)消费的增长。那么PIH意味着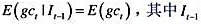 时期所知道的信息;此时,t代表年份。
时期所知道的信息;此时,t代表年份。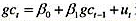 来检验持久收入假说。明确表述原假设和备择假设。你能得出什么结论?
来检验持久收入假说。明确表述原假设和备择假设。你能得出什么结论?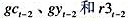 ,作为工具变量重新估计教材(16.35)。这些估计值与教材(16.36)中的那些估计值相比如何?
,作为工具变量重新估计教材(16.35)。这些估计值与教材(16.36)中的那些估计值相比如何?
















