 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
所谓迭代关系式,指如何从变量的前一个值推出其下一个值的公式或关系。迭代关系式的建立是解决迭代问题的关键,通常可以()或倒推的方法来完成。
A.理解
B.偏差
C.相合
D.顺推
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.理解
B.偏差
C.相合
D.顺推
如果结果不匹配,请 联系老师 获取答案
 更多“所谓迭代关系式,指如何从变量的前一个值推出其下一个值的公式或…”相关的问题
更多“所谓迭代关系式,指如何从变量的前一个值推出其下一个值的公式或…”相关的问题
使用TRAFFIC2.RAW中的数据。
(i)做prcfat对一个线性时间趋势、月份虚拟变量及变量wkends,unem,spdlaw和beltlw的OLS回归。利用教材方程(12.14)中的回归检验误差中的AR(1)序列相关。使用假定了严格外生回归元的检验说得过去吗?
(ii)利用尼威-韦斯特估计量中的4阶滞后,求spdlaw和beltlaw系数的序列相关和异方差-稳健标准误。这将如何影响这两个政策变量的统计显著性?
(iii)现在,利用迭代普莱斯-温斯顿程序估计模型,并将估计值与OLS估计值进行比较。政策变量的系数或统计显著性有重大变化吗?
利用DISCRIM.RAW中的数据回答本题。(也可参见第3章计算机习题c 3.8.)
(i)利用OLS估计模型
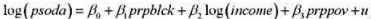
以常用形式报告结果。在5%的显著性水平上,相对一个双侧对立假设,β统计显著异于零吗?在1%的显著性水平上呢?
(ii)log(income)和prppov的相关系数是多少?每个变量都是统计显著的吗?报告双侧P值。
(iii)在第(i)部分的回归中增加变量log(hseval)。解释其系数并报告H0:βlog(hseval)=0的双侧p值。
(iv) 在第(ii) 部分的回归中, log(income) 和prppov的个别统计显著性有何变化?这些变量联合显著吗?(计算一个p值。)你如何解释你的答案?
(v)给定前面的回归结果,在确定一个邮区的种族构成是否影响当地快餐价格时,你会报告哪一个结果才最为可靠?
利用AFFAIRS.RAW中的数据。
(i)给定的数据中有多少是女人?变量naffairs是一个已婚的人婚外情的次数(尽管大部分的数据是按照一定的区间分组的)。从来没有过婚外情的女人的比例是多大?次数最多的是多少?
(ii)用age,yrsmarr,kids,educ,vryrel,smeral,slghtrel和notrel作为变量,估计一个泊松模型,解释vryrel的系数并以最大似然标准误为基础讨论t值。
(iii)现在得到了当方差和均值与教材(17.35)相关的情况下的标准误,相比于泊松MLE模型下的t值,本题估计出的t值的解释能力如何?
A.计算机对请求进行处理的时间
B.计算机处理完成后将响应送回终端的时间
C.从提交一个请求开始到首次产生响应为止(显示出结果)的一段时间间隔
D.把请求信息从键盘传送到计算机的时间
若将森林中的每棵树视作一个等价类,则Kruskal算法迭代过程所涉及的计算不外乎两类:

支持以上操作接口的数据结构,即所谓的独立集(disjoint set),亦称作并查集(union-find set)。
a)试基于此前介绍过的基本数据结构实现并查集,并用以组织Kruskal算法中的森林;
b)按你的实现,find()和union()接口的复杂度各是多少?相应地,Kruskal算法的复杂度呢?
(i)在方程(11.27)中添加一个线性时间趋势。在一阶差分方程中,时间趋势是必要的吗?
(ii)从式(11.27)中去掉时间趋势并添加变量ww2和pil(不要对虚拟变量进行差分)。这两个变量在5%的水平上是显著的吗?
(iii)用第(ii)部分中的模型估计LRP并求出其标准误。与从式(10.19)得到的结果相比较,在式(10.19)中gfr和pe是以水平值形式而非差分形式出现的。
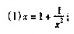
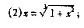
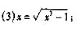
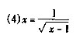
试分析由此所产生的迭代格式的收敛性?选一种收敛速度最快的格式求方程的根,要求误差不超过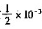 ,选一种收敛速度最慢或不收敛的迭代格式,用Aiken加速,其结果如何?
,选一种收敛速度最慢或不收敛的迭代格式,用Aiken加速,其结果如何?

















