

 如果结果不匹配,请
如果结果不匹配,请 
 更多“对回归和分类模型的评价中,准确率和召回率是最常用的指标。()”相关的问题
更多“对回归和分类模型的评价中,准确率和召回率是最常用的指标。()”相关的问题
A.学习率控制每次更新参数的幅度,学习率越大模型准确率越高
B.固定学习率比Adam自动调整学习率更快训练完成
C.过高的学习值会使损失值不降反升
D.学习率对模型训练时长有影响,对模型性能没有影响
A.⑤
B.①③④⑤
C.①②③④
D.①②④⑤
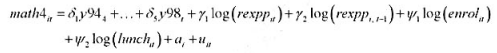
其中,因为滞后支出变量,第一个可用年份(基年)是1993年。
(i)用混合OLS估计模型, 并报告通常的标准误。为使得ai的期望值可以非零, 你应该与年度虚拟变量一起包含一个截距项。支出变量的估计效应是什么?求OLS残差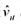 。
。
(ii)lunchit系数的符号在意料之中吗?解释系数的大小。你认为学区的贫穷率对考试通过率有很大的影响吗?
(iii)利用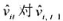 的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994~1998年的数据。验证存在很强的正序列相关,并讨论为什么。
的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994~1998年的数据。验证存在很强的正序列相关,并讨论为什么。
(iv)现在用固定效应法估计方程。滞后的支出变量仍显著吗?
(v)你为什么认为在固定效应估计中,注册学生人数和午餐项目变量不是联合显著的?

A.两者都是监督学习的方法
B.多项逻辑斯蒂回归模型也被称为softmax函数
C.两者都可被用来完成多类分类任务
D.逻辑斯帝回归是监督学习,多项逻辑斯蒂回归模型是非监督学习

其中,因为滞后支出变量,第一个可用年份(基年)是1993年。
(i)用混合OLS估计模型,并报告通常的标准误。为使得ai的期望值可以非零,你应该与年度虚拟变量一起包含一个截距项。支出变量的估计效应是什么?求OLS残差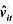 。
。
(ii)lunchit系数的符号在意料之中吗?解释系数的大小。你认为学区的贫穷率对考试通过率有很大的影响吗?
(iii)利用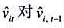 的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994-1998年的数据。验证存在很强的正序列相关,并讨论为什么。
的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994-1998年的数据。验证存在很强的正序列相关,并讨论为什么。
(iv)现在用固定效应法估计方程。滞后的支出变量仍显著吗?
(v)你为什么认为在固定效应估计中,注册学生人数和午餐项目变量不是联合显著的?
(vi)定义支出的总(或长期)效应为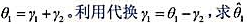 的标准误。
的标准误。
A.异方差
B.完全多重共线
C.遗漏变量偏差
D.虚拟变量陷阱
A.向前选择法是从模型中没有自变量开始,然后将所有自变量依次增加到模型中
B.向后剔除法是先对所有自变量拟合线性回归模型,然后依次将所有自变量剔除模型
C.逐步回归法是将向前选择法和向后剔除法结合起来,但不能保证得到的回归模型一定就显著
D.逐步回归法选择变量时,在前面步骤中增加的自变量在后面的步骤中有可能被剔除,而在前面步骤中剔除的自变量在后面的步骤中也可能重新进入到模型中
A.OpenVINO对模型训练具有显著性能提升
B.经过OpenVINO的模型优化可以提升模型准确率
C.OpenVINO除支持C++外,还支持Python语言接口
D.OpenVINO在使用前需要经过Intel官方购买并授权
















