

 如果结果不匹配,请
如果结果不匹配,请 
 更多“层次聚类有融合算法和分解算法两个基本算法。()”相关的问题
更多“层次聚类有融合算法和分解算法两个基本算法。()”相关的问题
第2题
集团集中性能管理KQI工单运营规范中,基于数据挖掘的KQI-KPI关联定界法,关联软硬采数据对无线侧问题进一步精确定位,建议数据挖掘应用方法有()。
A.NaiveBayes朴素贝叶斯算法
B.Pearson趋势关联分析+K-means自学习聚类
C.基于PNN的神经网络算法
D.k均值聚类算法
第6题
K-means算法的缺点不包括()A K必须是事先给定的 B 选择初始聚类中心 C 对于“噪声”和孤立点数
K-means算法的缺点不包括()
A K必须是事先给定的 B 选择初始聚类中心 C 对于“噪声”和孤立点数据是敏感的
D可伸缩、高效
第7题
若将森林中的每棵树视作一个等价类,则Kruskal算法迭代过程所涉及的计算不外乎两类:支持以上操
若将森林中的每棵树视作一个等价类,则Kruskal算法迭代过程所涉及的计算不外乎两类:

支持以上操作接口的数据结构,即所谓的独立集(disjoint set),亦称作并查集(union-find set)。
a)试基于此前介绍过的基本数据结构实现并查集,并用以组织Kruskal算法中的森林;
b)按你的实现,find()和union()接口的复杂度各是多少?相应地,Kruskal算法的复杂度呢?
第8题
关于混合模型聚类算法的优缺点,下面说法正确的是()。
A.当簇只包含少量数据点,或者数据点近似协线性时,混合模型也能很好地处理。
B.混合模型比K均值或模糊c均值更一般,因为它可以使用各种类型的分布。
C.混合模型很难发现不同大小和椭球形状的簇。
D.混合模型在有噪声和离群点时不会存在问题
第9题
问题描述:给定两个n×n矩阵A和B,试设计一个判定A和B是否互逆的蒙特卡罗算法(算法的计算时间应为
问题描述:给定两个n×n矩阵A和B,试设计一个判定A和B是否互逆的蒙特卡罗算法(算法的计算时间应为O(n2).
算法设计:设计一个蒙特卡罗算法,对于给定的矩阵A和B,判定其是否互逆.
数据输入:由文件input.txt给出输入数据.第1行有1个正整数n,表示矩阵A和B为n×n矩阵.接下来的2n行,每行有n个实数,分别表示矩阵A和B中的元素.
结果输出:将计算结果输出到文件output.txt.若矩阵A和B互逆,则输出“YES",否则输出“NO".
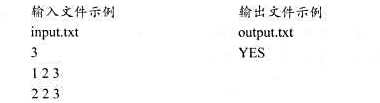

第10题
假定已知A∈的三角分解A=LU,试设计一个算法来计算A-1的(i,j)元素。
假定已知A∈的三角分解A=LU,试设计一个算法来计算A-1的(i,j)元素。
点击查看答案
假定已知A∈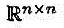 的三角分解A=LU,试设计一个算法来计算A-1的(i,j)元素。
的三角分解A=LU,试设计一个算法来计算A-1的(i,j)元素。
第11题
对任何非零偶数n,总可以找到奇数m和正整数k,使得n=m2k.为了求出两个n阶矩阵的乘积,可以
把一个n阶矩阵分成m×m个子矩阵,每个子矩阵有2k×2k个元素.当需要求2k×2k的子矩阵的积时,使用Strassen算法.设计一个传统方法与Strassen算法相结合的矩阵相乘算法,对任何偶数n,都可以求出两个n阶矩阵的乘积.并分析算法的计算时间复杂性.
点击查看答案
















