 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
从显在变量提炼潜在因子,并解决变量间的信息重叠问题,这种方法属于()。
A.因子分析
B.聚类分析
C.对应分析
D.回归分析
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.因子分析
B.聚类分析
C.对应分析
D.回归分析
如果结果不匹配,请 联系老师 获取答案
 更多“从显在变量提炼潜在因子,并解决变量间的信息重叠问题,这种方法…”相关的问题
更多“从显在变量提炼潜在因子,并解决变量间的信息重叠问题,这种方法…”相关的问题
用到CONSUMP.RAW中的数据。
(i)在教材例16.7中,用教材15.5节的方法检验在估计教材(16.35)时的那个过度识别约束。你的结论是什么?
(ii)由于潜在的数据度量问题和信息滞后,坎贝尔和曼昆(CampbellandMankiw,1990)使用所有变量的二阶滞后值作为工具变量。只用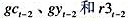 ,作为工具变量重新估计教材(16.35)。这些估计值与教材(16.36)中的那些估计值相比如何?
,作为工具变量重新估计教材(16.35)。这些估计值与教材(16.36)中的那些估计值相比如何?
(iii)将gy,对第(ii)部分的Ⅳ回归,并检验gy,与它们是否充分相关。这一点为什么重要?
A.包含CONSTANT选项
B.包含CONSTANT选项并初始化变量值
C.与在主体中声明的变量匹配
D.从数据库中检索适当的数据
A.主元回归可以一定程度上解决多重共线性带来的问题
B.增加样本容量可以消除多重共线性
C.岭回归可以缓解多重共线性带来的影响
D.多重共线性是指变量间存在很强的线性关系
A.压力比温度的主效应更显著
B.两因子之间存在交互作用
C.压力的P值肯定会小于0.05,所以可称为统计上显著因子
D.压力值从低到高变化会导致响应变量均值变小
A.Python不需要显式声明变量类型,在第一次变量赋值时由值决定变量的类型
B.变量通过变量名访问
C.变量必须在创建和赋值后使用
D.变量PI与变量Pi被看作相同的变量
在宏观经济分析中,潜在就业量()。
A.是一个外生变量
B.是固定不变的
C.取决于投资、价格水平等宏观经济变量
D.取决于产量、消费等指标
A.lm-1
B.l-1
C.m-1
D.l(m-1)

















