 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
令虚拟变量grad表示一个体育生5年内是否在一所大学毕业。令hs GPA和SAT分别表示高中平均成绩和SAT考试分数。令study表示每周参加正规学习的小时数。假定利用420个体育生数据, 得到如下logit模型:
令虚拟变量grad表示一个体育生5年内是否在一所大学毕业。令hs GPA和SAT分别表示高中平均成绩和SAT考试分数。令study表示每周参加正规学习的小时数。假定利用420个体育生数据, 得到如下logit模型: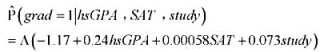 其中,A(z)=cxp(z)/[l+exp(z)]为逻辑斯蒂函数。保持hsGPA和SAT固定在3.0和1200的水平上,针对每周在正规学习场所学习10个小时与学习5个小时的体育生,计算其毕业概率的估计差异。
其中,A(z)=cxp(z)/[l+exp(z)]为逻辑斯蒂函数。保持hsGPA和SAT固定在3.0和1200的水平上,针对每周在正规学习场所学习10个小时与学习5个小时的体育生,计算其毕业概率的估计差异。
暂无答案
 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案

 更多“令虚拟变量grad表示一个体育生5年内是否在一所大学毕业。令…”相关的问题
更多“令虚拟变量grad表示一个体育生5年内是否在一所大学毕业。令…”相关的问题
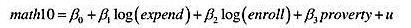
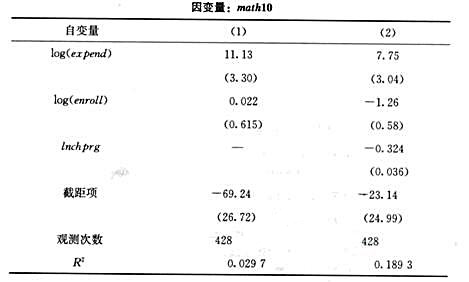
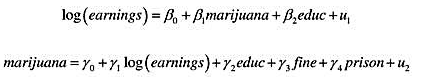

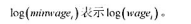

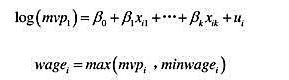
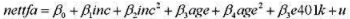
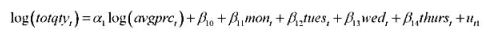

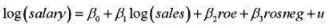
 的解释及其统计显著性。
的解释及其统计显著性。















