

 如果结果不匹配,请
如果结果不匹配,请 
 更多“25个雇员的随机样本的平均周薪为130元,试问此样本是否取自…”相关的问题
更多“25个雇员的随机样本的平均周薪为130元,试问此样本是否取自…”相关的问题
第1题
数据集SMOKE.RAW包含美国成人个人随机样本在抽烟行为和其他变量方面的信息。变量cigs为(平均)每
数据集SMOKE.RAW包含美国成人个人随机样本在抽烟行为和其他变量方面的信息。变量cigs为(平均)每天抽烟的数量。你是否认为在美国这个总体中,cigs具有正态分布?试做解释。
第2题
某快餐店想估计每位顾客午餐的平均花费金额,在为期3周的时间里选取49名顾客组成了一个简单随机样本。假定总体标准差为15元,样本均值为120元,在95%的置信水平下进行区间估计。则以下正确的是()
A.置信区间为(115.8,124.2)
B.样本均值的标准误差为2.143
C.置信区间的估计误差为4.2
D.置信区间的半长为8.4
第3题
利用JTRAIN.RAW,以确定工作培训津贴对每个雇员工作培训小时数的影响。三年的基本模型是: (i)用
利用JTRAIN.RAW,以确定工作培训津贴对每个雇员工作培训小时数的影响。三年的基本模型是:

(i)用固定效应法估计方程。在此估计中利用了多少个企业?如果每个企业都有这三年的所有变量数据(特别是hrsemp的数据),总观测个数会是多少?
(ii)解释grant的系数并评论它的显著性。
(iii)grant-1不显著有什么惊人之处吗?请解释。
(iv)平均地说,更大的企业为其职工提供了更多还是更少的培训?差别有多大?(比方说,职工多10%的企业,培训的平均小时数增多或减少了多少?)
第5题
张先生在农贸市场经营摊位,主营粮油和大米。基本无淡旺季,平均每天营业额在2250元/天,毛利在30%
左右。有一雇员,基本月薪1500元。有一面包车拉货,车费2000元/月(含保险、年检等)。店面租金600元/月,个人保险3600元/年,招待费1500元/月,检疫费1400元/月,水电费250元/月。家庭开支2500元/月。住房为按揭,月供900元,还有八年还清。则客户的月可支配收入为多少元()
点击查看答案
A.67500
B.20250
C.9300
D.10200
第6题
企业购入原材料,买价1 000元,增值税(进项税)170元,发生的运费130元,入库后发生的挑选整理费9
0元,则该批材料的实际成本为().
点击查看答案
A.1 390元
B.1 300元
C.1 170元
D.1 130元
第8题
设 为来自总体N(μ,σ2)的简单随机样本, 为样本均值,已知 是σ2的无偏估计(或ET=σ2),
设 为来自总体N(μ,σ2)的简单随机样本, 为样本均值,已知 是σ2的无偏估计(或ET=σ2),
点击查看答案
设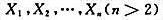 为来自总体N(μ,σ2)的简单随机样本,
为来自总体N(μ,σ2)的简单随机样本,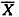 为样本均值,已知
为样本均值,已知 是σ2的无偏估计(或ET=σ2),则常数C必为()
是σ2的无偏估计(或ET=σ2),则常数C必为()
A.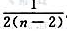
B.
C.
D.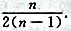
第9题
设为来自总体N(0,1)的简单随机样本,又为样本均值,S2为样本方差,则()A.B.C.D.
设为来自总体N(0,1)的简单随机样本,又为样本均值,S2为样本方差,则()A.B.C.D.
点击查看答案
设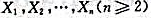 为来自总体N(0,1)的简单随机样本,又为样本均值,S2为样本方差,则()
为来自总体N(0,1)的简单随机样本,又为样本均值,S2为样本方差,则()
A.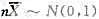
B.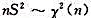
C.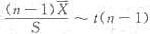
D.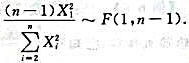
第10题
设总体X的均值E(X)=μ,方差D(X)=σ2,X1,X2,...,Xn为来自总体的简单随机样本,
设总体X的均值E(X)=μ,方差D(X)=σ2,X1,X2,...,Xn为来自总体的简单随机样本,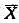 为样本均值,求Xi-和Xj-的相关系数(i≠j)。
为样本均值,求Xi-和Xj-的相关系数(i≠j)。
















