 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
假如我们建立一个60000个特征,1000万数据集的机器学习模型,我们怎么有效的应对这样的大规模数据的训练()。
A.对样本进行抽样,在经过抽样的样本上训练
B.应用PCA算法降维,减少特征数量
C.根据重要性对特征进行筛选
D.以上所有
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.对样本进行抽样,在经过抽样的样本上训练
B.应用PCA算法降维,减少特征数量
C.根据重要性对特征进行筛选
D.以上所有
如果结果不匹配,请 联系老师 获取答案
 更多“假如我们建立一个60000个特征,1000万数据集的机器学习…”相关的问题
更多“假如我们建立一个60000个特征,1000万数据集的机器学习…”相关的问题
A公司维修部门在不同维修水平下的维修费用资料如下:
维修工时在50000小时的水平下,维修费用可以分解如下:
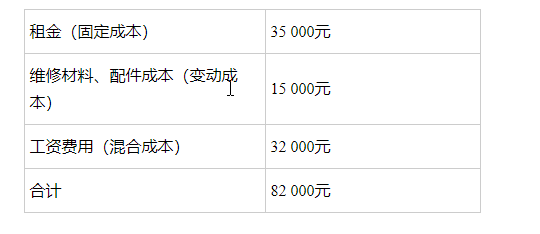 问题:建立维修部门工资费用的成本性态模型,并估计维修部门工作60000个小时的维修费用。
问题:建立维修部门工资费用的成本性态模型,并估计维修部门工作60000个小时的维修费用。
A.数字化、集成性、多样性、交互性、非线性
B.数字化、分散性、交互性、多样性、非线性
C.数字化、分散性、逻辑性、交互性、线性
D.数字化、集成性、多样性、交互性、线性
A.加强水质基础数据调查工作,为制定饮用水标准、确保饮用水安全提供科学依据
B.加强饮用水水源地管理,建立饮用水保护区,进行水源地生态修复
C.加强适应水质特征的技术集成研究,形成不同污染特征的饮用水安全保障技术
D.以上均正确
A.使用前向特征选择方法
B.使用后向特征排除方法
C.我们先把所有特征都使用,去训练一个模型,得到测试集上的表现.然后我们去掉一个特征,再去训练,用交叉验证看看测试集上的表现.如果表现比原来还要好,我们可以去除这个特征
D.查看相关性表,去除相关性最高的一些特征

















