 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
在相关分析中,估计标准误起着说明回归直线代表性大小的作用,即()。
A.估计标准误大,回归直线代表性小,回归直线实用价值大
B.估计标准误大,回归直线代表性小,回归直线实用价值小
C.估计标准误小,回归直线代表性小,回归直线实用价值小
D.估计标准误大,回归直线代表性大,回归直线实用价值大
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.估计标准误大,回归直线代表性小,回归直线实用价值大
B.估计标准误大,回归直线代表性小,回归直线实用价值小
C.估计标准误小,回归直线代表性小,回归直线实用价值小
D.估计标准误大,回归直线代表性大,回归直线实用价值大
如果结果不匹配,请 联系老师 获取答案
 更多“在相关分析中,估计标准误起着说明回归直线代表性大小的作用,即…”相关的问题
更多“在相关分析中,估计标准误起着说明回归直线代表性大小的作用,即…”相关的问题

其中,因为滞后支出变量,第一个可用年份(基年)是1993年。
(i)用混合OLS估计模型,并报告通常的标准误。为使得ai的期望值可以非零,你应该与年度虚拟变量一起包含一个截距项。支出变量的估计效应是什么?求OLS残差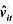 。
。
(ii)lunchit系数的符号在意料之中吗?解释系数的大小。你认为学区的贫穷率对考试通过率有很大的影响吗?
(iii)利用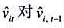 的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994-1998年的数据。验证存在很强的正序列相关,并讨论为什么。
的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994-1998年的数据。验证存在很强的正序列相关,并讨论为什么。
(iv)现在用固定效应法估计方程。滞后的支出变量仍显著吗?
(v)你为什么认为在固定效应估计中,注册学生人数和午餐项目变量不是联合显著的?
(vi)定义支出的总(或长期)效应为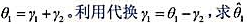 的标准误。
的标准误。
利用BARIUM.RAW中的数据。
(i)用前119次观测(即不包含1988年的最后12个月观测),估计线性趋势模型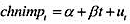 。这个回归的标准误是什么?
。这个回归的标准误是什么?
(ii)同样用除了最后12个月以外的所有数据,估计chnimp的一个AR(1)模型。把这个回归的标准误与第(i)部分中的标准误相比较。哪一个模型提供了更好的样本内拟合?
(iii)用第(i)和第(ii)部分中的模型计算1988年12个月的提前一期预测误差。(每个方法都应该得到12个预测误差。)计算并比较这两种方法的RMSE和MAE。就样本外提前一期预测而言,哪种方法效果更好?
(iv)在第(i)部分的回归中添加月度虚拟变量。它们是联合显著的吗?(当我们检验联合显著性时,不必担心误差中轻度的序列相关。)
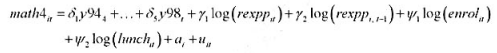
其中,因为滞后支出变量,第一个可用年份(基年)是1993年。
(i)用混合OLS估计模型, 并报告通常的标准误。为使得ai的期望值可以非零, 你应该与年度虚拟变量一起包含一个截距项。支出变量的估计效应是什么?求OLS残差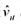 。
。
(ii)lunchit系数的符号在意料之中吗?解释系数的大小。你认为学区的贫穷率对考试通过率有很大的影响吗?
(iii)利用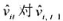 的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994~1998年的数据。验证存在很强的正序列相关,并讨论为什么。
的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994~1998年的数据。验证存在很强的正序列相关,并讨论为什么。
(iv)现在用固定效应法估计方程。滞后的支出变量仍显著吗?
(v)你为什么认为在固定效应估计中,注册学生人数和午餐项目变量不是联合显著的?

数;(2)计算回归平方和及总的平方和;(3)计算估计标准误差。
使用TRAFFIC2.RAW中的数据。
(i)做prcfat对一个线性时间趋势、月份虚拟变量及变量wkends,unem,spdlaw和beltlw的OLS回归。利用教材方程(12.14)中的回归检验误差中的AR(1)序列相关。使用假定了严格外生回归元的检验说得过去吗?
(ii)利用尼威-韦斯特估计量中的4阶滞后,求spdlaw和beltlaw系数的序列相关和异方差-稳健标准误。这将如何影响这两个政策变量的统计显著性?
(iii)现在,利用迭代普莱斯-温斯顿程序估计模型,并将估计值与OLS估计值进行比较。政策变量的系数或统计显著性有重大变化吗?
(i)考虑静态非观测效应模型

其中,enrolit表示学区总注册学生人数,lunchit表示学区中学生有资格享受学校午餐计划的百分数。(因此lunchit是学区贫穷率的一个相当好的度量指标。)证明:若平均每个学生的真实支出提高10%,则math4it约改变β1/10个百分点。
(ii)利用一阶差分估计第(i)部分中的模型。最简单的方法就是在一阶差分方程中包含一个截距项和1994~1998年度虚拟变量。解释支出变量的系数。
(iii)现在,在模型中添加支出变量的一阶滞后,并用一阶差分重新估计。注意你又失去了一年的数据,所以你只能用始于1994年的变化。讨论即期和滞后支出变量的系数和显著性。
(iv)求第(iii)部分中一阶差分回归的异方差-稳健标准误。支出变量的这些标准误与第(iii)部分相比如何?
(v)现在,求对异方差性和序列相关都保持稳健的标准误。这对滞后支出变量的显著性有何影响?
(vi)通过进行一个AR(1)序列相关检验,验证差分误差rit=Δuit含有负序列相关。
(vii)基于充分稳健的联合检验,模型中有必要包含学生注册人数和午餐项目变量吗?
利用JTRAIN3.RAW中的数据。
(i)估计简单回归模型re78=β0+β1train+u,并用常用格式报告结论。基于这个回归,1976年和1977年的工作培训看上去对1978年的真实劳动工资有正的影响吗?
(ii)现在使用真实劳动工资的变化cre=re78-re75作为因变量。(由于我们假定1975年之前没有工作培训,所以我们没有必要对train进行差分。也就是说,如果我们定义ctrain=train78-train75,那么,由于train75=0,所以ctrain=train78.)现在,培训的估计影响有多大?讨论它与第(i)部分估计值的比较。
(iii)利用通常的OLS标准误和异方差-稳健标准误求培训效应的95%置信区间,并描述你的结论。
利用HPRICE1.RAW中的数据。
(i)估计模型
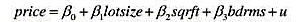
并按通常的格式报告你的结果,包括回归标准误。当我们代入lotsize=10000,sqrft=2300和bdrms=4时,求出预测价格,将这个价格四舍五入到美元。
(ii)做一个回归,使你能得到第(i)部分中预测值的一个95%的置信区间。注意,由于四舍五入的误差,你的预测将多少有些不同。
(iii)令price0为具有第(i)部分和第(ii)部分所述特征的住房的未知未来售价。求出price0的一个95%的置信区间,并对这个置信区间的宽度进行评论。
利用LOANAPP.RAW中的数据。
(i)估计第7章的计算机练习C8第(iii)部分中的方程,计算其异方差-稳健的标准误。将βwhite的95%的置信区间与非稳健的置信区间相比较。
(ii)由第(i)部分的回归计算拟合值。其中有没有哪个估计值小于0?有没有哪个估计值大于1?而这些情况对加权最小二乘估计的应用意味着什么?

















