

 如果结果不匹配,请
如果结果不匹配,请 
 更多“常用的数据分析方法有()。”相关的问题
更多“常用的数据分析方法有()。”相关的问题
推断性统计学常用的方法是()。
A.用表格来概括数据
B.用图形来概括数据
C.用数论来概括数据
D.回归分析模型
利用JTRAIN3.RAW中的数据。
(i)估计简单回归模型re78=β0+β1train+u,并用常用格式报告结论。基于这个回归,1976年和1977年的工作培训看上去对1978年的真实劳动工资有正的影响吗?
(ii)现在使用真实劳动工资的变化cre=re78-re75作为因变量。(由于我们假定1975年之前没有工作培训,所以我们没有必要对train进行差分。也就是说,如果我们定义ctrain=train78-train75,那么,由于train75=0,所以ctrain=train78.)现在,培训的估计影响有多大?讨论它与第(i)部分估计值的比较。
(iii)利用通常的OLS标准误和异方差-稳健标准误求培训效应的95%置信区间,并描述你的结论。
数据集401KSUBS.RAW包含了净金融财富(nenfa)、被调查者年龄(age)、家庭年收入(inc)、家庭规模(fsize)方面的信息,以及参与美国个人的特定养老金计划方面的信息。财富和收入变量都以千美元为单位记录。对于这里的问题,只使用无子女已婚者数据(marr=1,fsize=2)。
(i)数据集中有多少无子女已婚夫妇?
(ii)利用OLS估计模型
nettfa=β0+β1inc+β2age+u;
并以常用格式报告结果。解释斜率系数。斜率估计值有何惊人之处吗?
(iii)第(ii)部分的回归截距有重要意义吗?请解释。
(iv)在1%的显著性水平上,针对H0:β2>1检验H0: β2=1,求出p值。你能拒绝H0吗?
(V)如果你做一个nettfa对inc的简单回归,inc的斜率估计值与第(ii)部分的估计值有很大不同吗?为什么?
1、在分析资产负债表项目之间的关系时,最常用的分析性复核方法是()
A、趋势分析法
B、回归分析法
C、比率分析法
D、绝对额比较法
A.决策树、对数回归、关联模式
B.K均值法、SOM神经网络
C.Apriori算法、FP-Tree算法
D.RBF神经网络、K均值法、决策树
利用DISCRIM.RAW中的数据回答本题。(也可参见第3章计算机习题c 3.8.)
(i)利用OLS估计模型
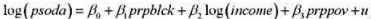
以常用形式报告结果。在5%的显著性水平上,相对一个双侧对立假设,β统计显著异于零吗?在1%的显著性水平上呢?
(ii)log(income)和prppov的相关系数是多少?每个变量都是统计显著的吗?报告双侧P值。
(iii)在第(i)部分的回归中增加变量log(hseval)。解释其系数并报告H0:βlog(hseval)=0的双侧p值。
(iv) 在第(ii) 部分的回归中, log(income) 和prppov的个别统计显著性有何变化?这些变量联合显著吗?(计算一个p值。)你如何解释你的答案?
(v)给定前面的回归结果,在确定一个邮区的种族构成是否影响当地快餐价格时,你会报告哪一个结果才最为可靠?
















