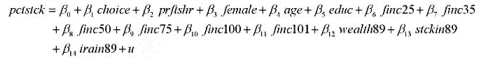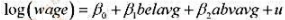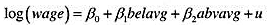题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
数据集401KSUBS.RAW包含了净金融财富(nenfa)、被调查者年龄(age)、家庭年收入(inc)、家庭规模(fsi
数据集401KSUBS.RAW包含了净金融财富(nenfa)、被调查者年龄(age)、家庭年收入(inc)、家庭规模(fsize)方面的信息,以及参与美国个人的特定养老金计划方面的信息。财富和收入变量都以千美元为单位记录。对于这里的问题,只使用无子女已婚者数据(marr=1,fsize=2)。
(i)数据集中有多少无子女已婚夫妇?
(ii)利用OLS估计模型
nettfa=β0+β1inc+β2age+u;
并以常用格式报告结果。解释斜率系数。斜率估计值有何惊人之处吗?
(iii)第(ii)部分的回归截距有重要意义吗?请解释。
(iv)在1%的显著性水平上,针对H0:β2>1检验H0: β2=1,求出p值。你能拒绝H0吗?
(V)如果你做一个nettfa对inc的简单回归,inc的斜率估计值与第(ii)部分的估计值有很大不同吗?为什么?
查看答案

 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案

 更多“数据集401KSUBS.RAW包含了净金融财富(nenfa)…”相关的问题
更多“数据集401KSUBS.RAW包含了净金融财富(nenfa)…”相关的问题