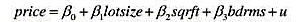题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
考虑简单回归模型令z为x的二值工具变量。运用式(15.10),ⅣV估计量,可以写成:其中,是zi=0的那
考虑简单回归模型令z为x的二值工具变量。运用式(15.10),ⅣV估计量,可以写成:其中,是zi=0的那
考虑简单回归模型
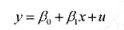
令z为x的二值工具变量。运用式(15.10),ⅣV估计量,可以写成: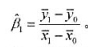 其中,
其中,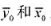 是zi=0的那部分样本中yi和xi的样本平均值,而
是zi=0的那部分样本中yi和xi的样本平均值,而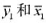 是zi=1的那部分样本中yi和xi的样本平均值。该估计量称为群组估计量, 它是由沃尔德(Wald, 1940) 最先提出。
是zi=1的那部分样本中yi和xi的样本平均值。该估计量称为群组估计量, 它是由沃尔德(Wald, 1940) 最先提出。
查看答案

 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案

 更多“考虑简单回归模型令z为x的二值工具变量。运用式(15.10)…”相关的问题
更多“考虑简单回归模型令z为x的二值工具变量。运用式(15.10)…”相关的问题
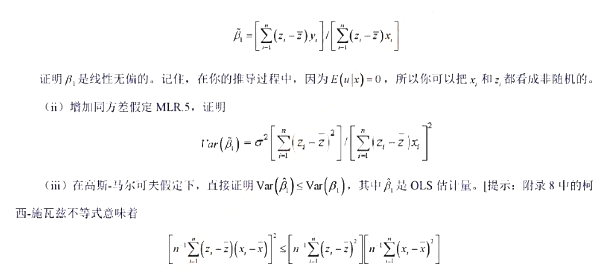
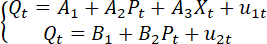
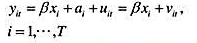
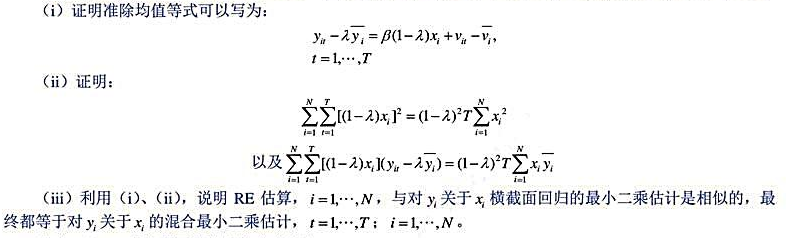
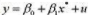 ,其中我们对
,其中我们对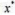 有m种度量,并记为
有m种度量,并记为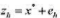 ,
,

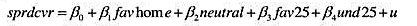
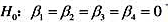 下,模型中不存在异方差性。
下,模型中不存在异方差性。